14. 数据结构篇:散列表
散列表的时间复杂度为什么是O(1)?
散列表其实是数组的一种扩展,用的是数组随机访问的特性。散列表以 key,value 的形式存储数据,散列表的 key 通过散列函数计算映射到数组的下标,这个计算出的下标就是我们常说的散列值,或者叫哈希值。
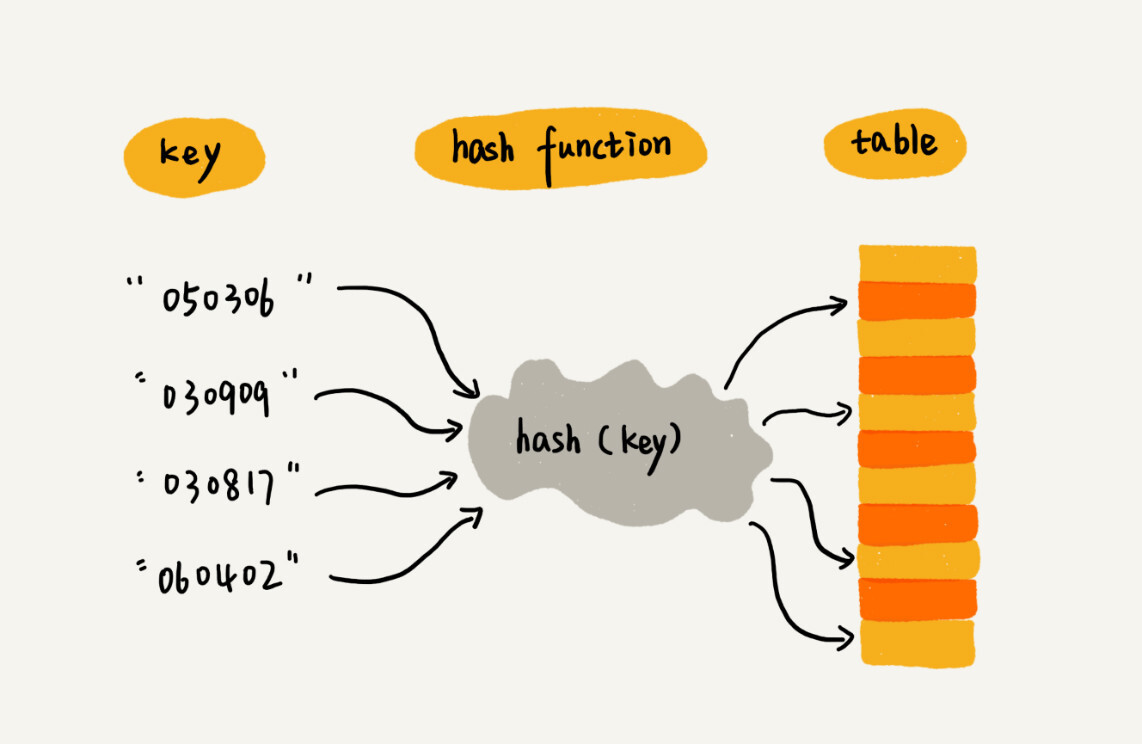
散列函数
散列函数可以定义成 hash(key),一个散列函数要满足三点要求:
- 散列函数计算得到的散列值是一个非负整数;
- 如果 key1 = key2,那 hash(key1) == hash(key2);
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
第 1,2 点好理解,散列值等于数组的下标,是一个非负整数,相同的 key 经过相同的散列函数后的值也是相同的。对于第 3 点,因为数组的长度有限,要把任意的 key 散列到有限的数组中,必然会存在散列冲突,所以不同的 key,经过散列计算后,有可能会落到同一个数组下标中。
散列冲突
解决散列冲突有两种方法:
1. 开放寻址法
核心思想:如果出现了散列冲突,就重新探测一个空闲位置插入数据。
探测方法主要有这几种:
- 线性探测:如果散列的位置已被占用,就从当前位置依次往后找,直到找到空闲位置为止。查找过程类似
- 二次探测:线性探测的步长为 1,它探测的下标序列就是 hash(key) + 0, hash(key)+1, ….而二次探测的步长变为原来的二次方,下标序列为 hash(key)+0,hash(key)+12,hash(key)+22,…
- 双重散列:使用一组散列函数hash1(key),hash2(key),hash3(key)…,先使用第一个散列函数,如果计算的存储位置已被占用,再使用第二个散列函数计算,依次类推,直到找到空闲的存储位置。
散列表一般使用装载因子来表示空位的多少,计算公式为:
散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
装载因子越大,说明空闲位置越少,越容易产生冲突。
2. 链表法
一般也叫拉链法。在散列表中,每个”槽位”对应一条链表,所有散列值相同的元素都会放到槽位对应的链表中。
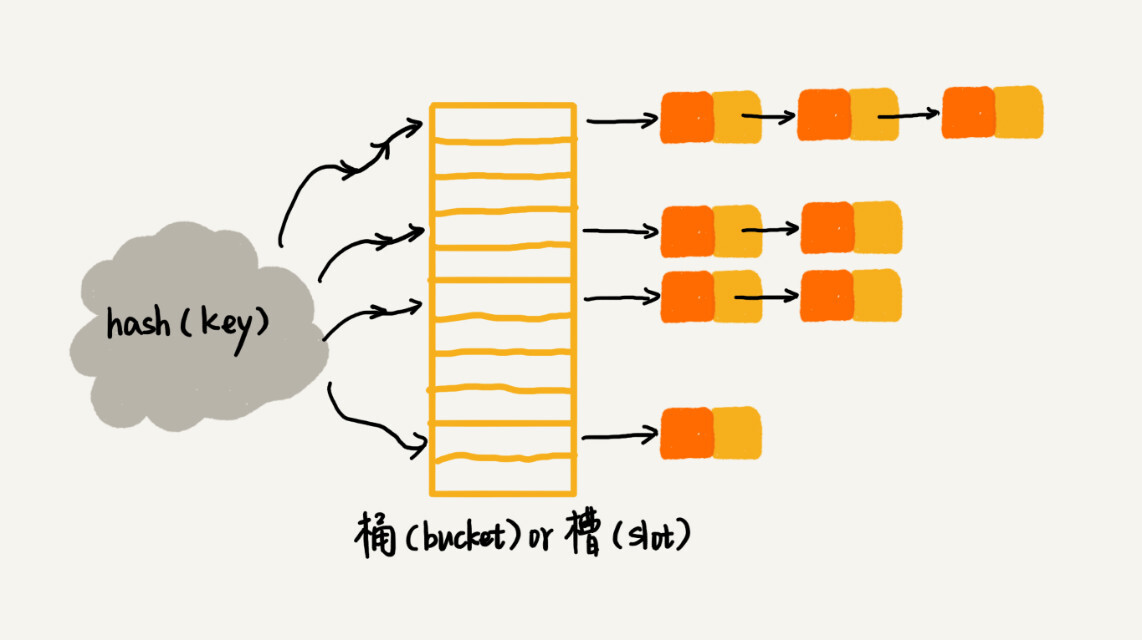
插入时,只需要通过散列函数计算出对应槽位,将其插入到对应链表的末尾,插入的时间复杂度为 O(1)。
查找或删除操作与插入类似,先通过散列函数计算槽位,然后遍历链表找到对应的值。时间复杂度,与链表的长度成正比。
设计一个工业级散列表
工业级的散列表有这样几点要求:
- 支持快速的查询、插入、删除操作
- 内存占用合理,不能浪费过多的内存空间
- 性能稳定,极端情况下,散列表的性能也不会退化到无法接受的情况
实现这样一个散列表,需要从三个方面来考虑:
- 设计一个合适的散列函数
- 定义装载因子,并且设计动态扩容策略
- 选择合适的散列冲突解决方法
动态扩容
设定一个合适的阈值,当装载因子超过阈值的时候,启动动态扩容,步骤如下:
- 重新申请一个更大的散列表,比如申请一个原来两倍大小的空间。
- 当有新数据插入时,将新数据插入到新散列表中,同时从旧的散列表中取出一个数据插入到新散列表中;经过多次插入操作后,旧的散列表的数据就一点点搬移到新散列表中了。
- 查询时,先从新散列表中查找,如果没有找到,再去旧的散列表中查找。
上面的动态扩容方法也叫 渐进式哈希 方法,也是 Redis 的 hash 结构扩容使用的方法。
LRU 缓存淘汰算法
一个 LRU 缓存淘汰算法核心思想如下:
当要缓存某个数据时,先查找这个数据,如果找到了,则将此数据删除,同时将这个数据放到头部;如果没找到,判断缓存是否已满,如果缓存满了,则把尾部的数据删除,再把数据插入到头部,如果缓存没满,则直接将数据插入到头部。
用一个单链表可以实现这样一个缓存淘汰系统,不过会比较低效,操作数据的时间复杂度为 O(n)。
而借助散列表和一个双向链表可以使用 O(1) 时间复杂度的 LRU 缓存淘汰算法。
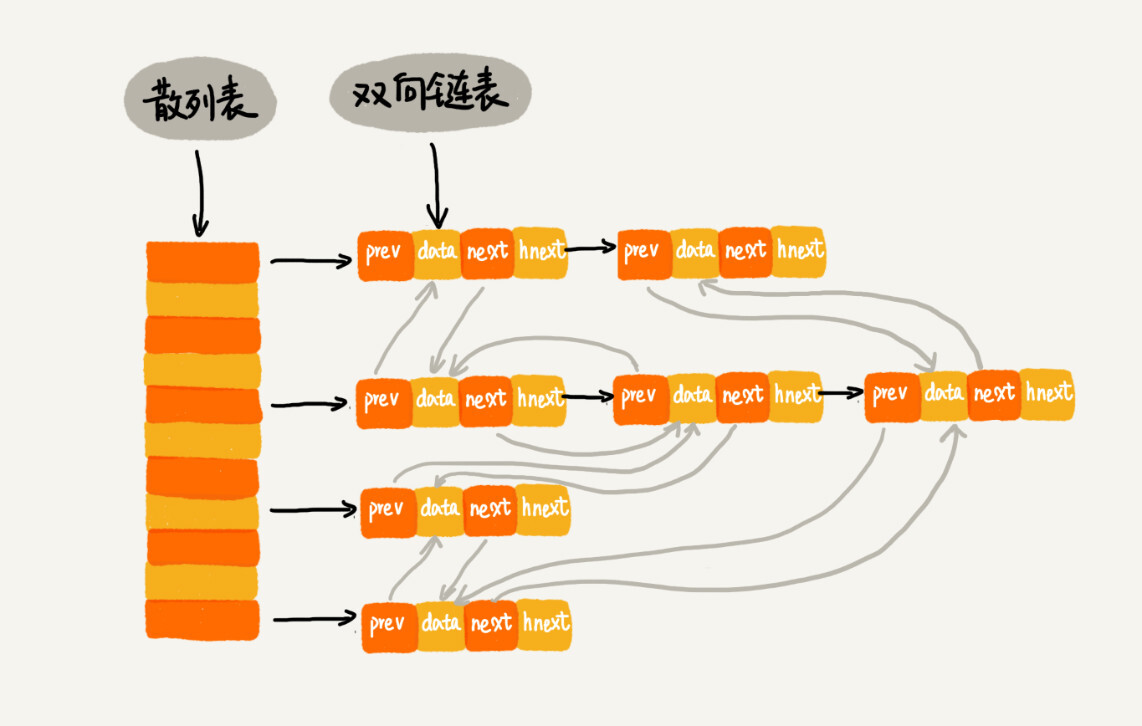
查找数据时,可以通过散列表在 O(1) 的时间复杂度内定位到一个数据,而删除、插入操作,可通过双向链表在 O(1) 的时间复杂度内完成,因此,散列表和双向链表的组合,可以实现一个高效的、支持 LRU 缓存淘汰系统。
散列表的 LRU 缓存淘汰算法实现:
# -*- coding: utf-8 -*-
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.capacity = capacity
self.cache = OrderedDict()
def set(self, key, value):
if key in self.cache:
self.cache.pop(key)
if len(self.cache) >= self.capacity:
self.cache.popitem(last=False)
# 只有OrderedDict才有popitem(last=Flase)这个参数,
# 而dict的popitem()里不能加参数
self.cache[key] = value
def get(self, key):
if key in self.cache:
value = self.cache[key]
self.cache.pop(key)
self.cache[key] = value
return value
return None
小结
散列表和链表(或跳表)经常会结合在一起使用。散列表是一种动态数据结构,可以支持非常高效的插入、删除、查找操作,但是散列表中的数据是通过散列函数打乱之后无规律存储的,它无法支持按照某种顺序快速地遍历数据,但是和链表/跳表结合使用,可以使用顺序的插入和遍历查找。

关注微信公众账号「曹当家的」,订阅最新文章推送