13. 数据结构篇:跳表
定义
如果数据存储在数组中,可以使用二分查找算法快速查找元素,但是如果数据存储在链表中,该如何快速高效地查找元素呢?实际上,利用二分的思想,只需要对链表稍加改造,变成跳表,就可以实现高效的查找元素。
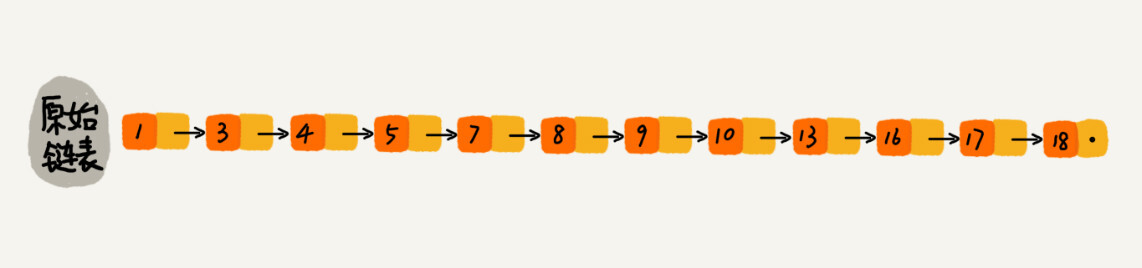
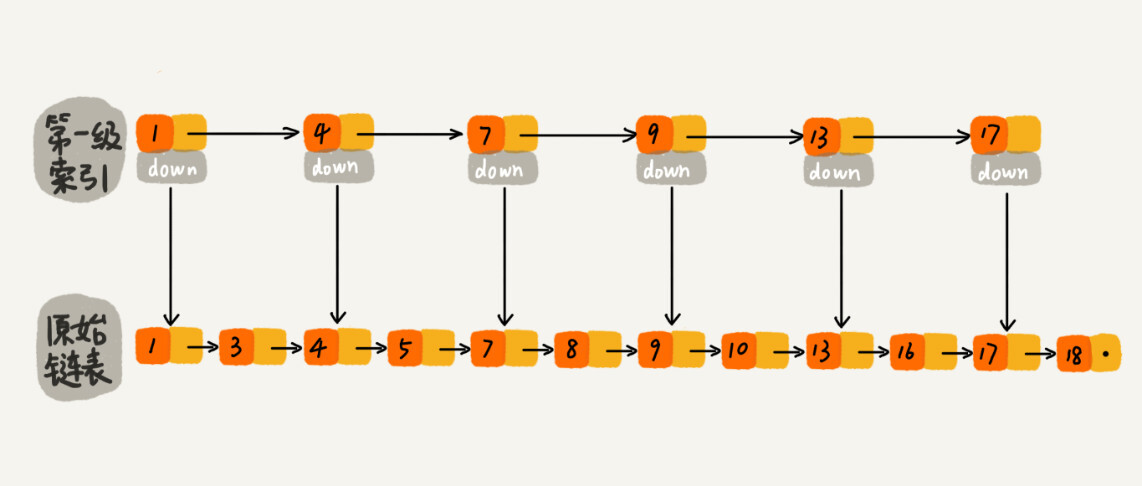
原始链表的每两个结点向上提取,建立一级索引,并通过 down 指针下降定位到下一层的元素。查找元素的时候,先在索引层遍历,当遍历到下一个元素比需要查找的元素大时,就下降一层,继续遍历。
加了一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。
如果继续往上提取结点,建立多级索引,那么查找效率的提升会非常明显:
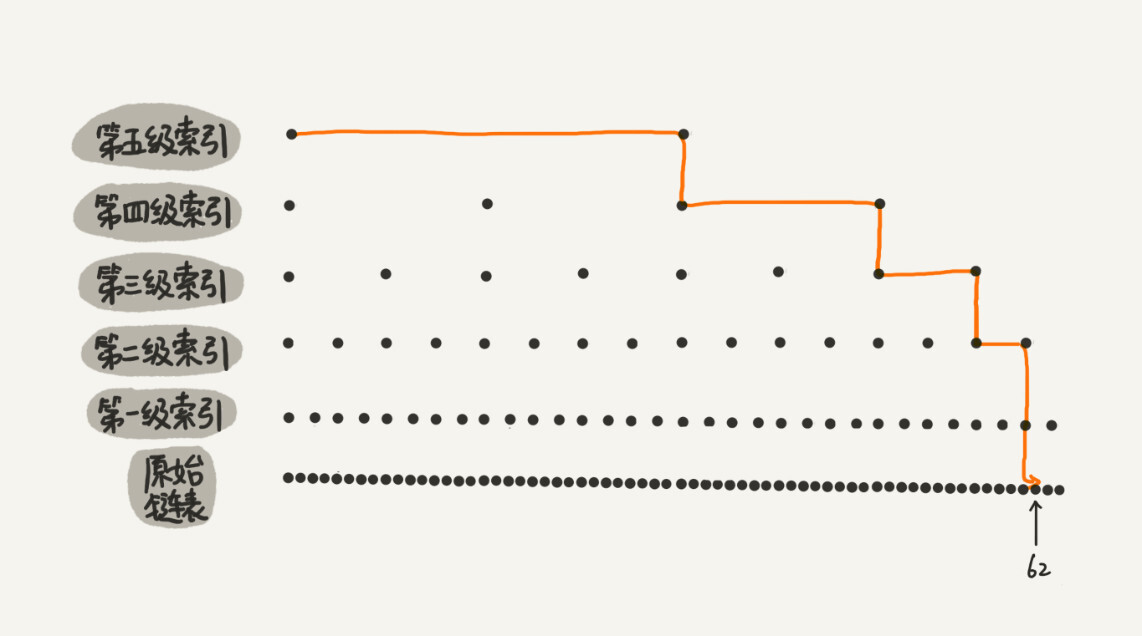
这种在链表上添加多级索引的结构,就是跳表。
跳表查询性能分析
时间复杂度
假设原始链表有 n 个结点,如果对链表的每两个结点向上提取建立索引,直到最高级的索引结点个数为 2, 那么第一级索引的结点数为 n/2,第二级索引结点数 n/4,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,每一级最多需要遍历 m 个结点,那么跳表查询的时间复杂度为 O(h*m),下面来求 h 和 m。
第 h 级索引的结点个数为 2, 根据上面的公式,n / 2h = 2,h = log2n;那么,m 如何求解呢?
假设要查询 x,第 k 级索引上查找时,发现 y < x < z,于是从 y 结点 下降到 k - 1 级索引,第 k - 1 级索引中,y 和 z 之间最多只需要遍历 3 个结点,以此类推,在每一级索引最多只需要遍历 3 个结点,因此 m = 3。
所以,可以得出,跳表的时间复杂度为 O(logn)。
空间复杂度
跳表的空间复杂度为第一级索引到第 k 级索引的总结点数 + 指针占用的空间。这里暂时忽略指针的占用,那么每一级索引的结点总数是一个等比数列:

这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以跳表的空间复杂度为 O(n)。
如果每 3 级抽取一个结点建立索引,那么索引的结点大约就是 n/3+n/9+n/27+…+9+3+1=n/2。减小了一半。
跳表的动态插入和删除
因为链表的插入和删除操作只需要改变指针,时间复杂度都是 O(1),但是需要找到插入或删除的位置,因此跳表的插入和删除实际上都是耗在了查询操作上。因此,插入和删除操作的时间复杂度为 O(logn)。
对于插入操作,如果两个结点直接插入了太多的数据,会导致跳表退化成单链表
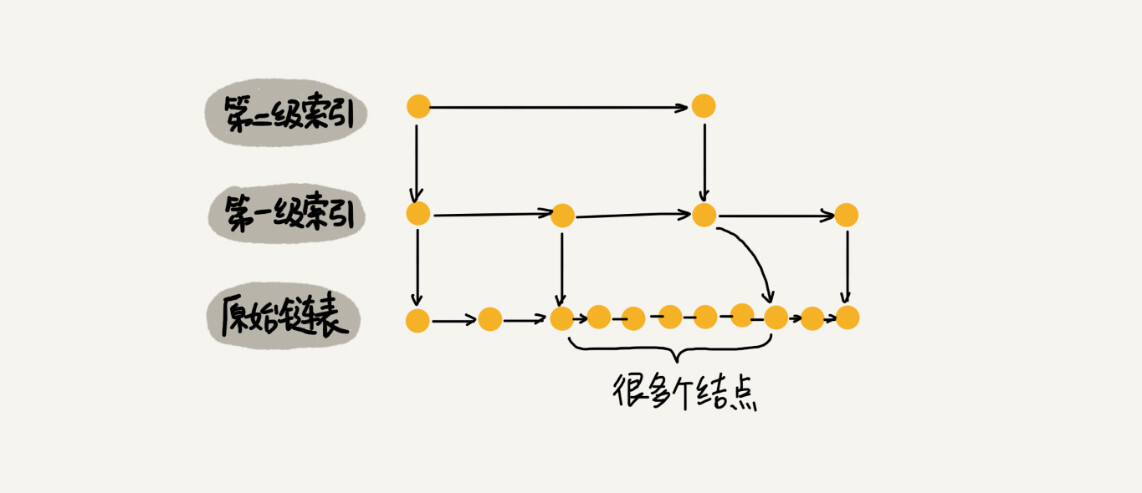
为了维护跳表的平衡性,每次插入结点时,使用随机函数生成一个随机数 k,来决定将这个结点同时插入第 1 级到第 k 级索引中。
扩展
Redis 的有序集合为什么用跳表来实现,而不是红黑树?
Redis 的 zset 主要操作有这几种:
- 插入一个数据: zadd
- 删除一个数据: zrem
- 查找一个数据(分值,排名):zscore,zrank
- 按照区间查找数据:zrange(start, end)
- 迭代输出有序序列:zrangebyrank
其中,插入、删除、查找以及迭代输出有序序列这几个操作,也可以用红黑树完成,时间复杂度和跳表一样,但是,按照区间查找元素操作,红黑树的效率没有跳表高。
跳表查找区间元素,可以在 O(logn) 时间复杂度内定位到区间的起点,然后顺序往后遍历就可以了,非常高效。

关注微信公众账号「曹当家的」,订阅最新文章推送