5. 数据结构篇:如何写出正确的链表代码?
LeetCode 关于链表的题目主要有以下几个:
- 链表的反转
- 合并有序链表
- 旋转链表
- 实现一个环形链表
- 删除链表的结点
- 求链表的中间结点
这几个都是比较难的操作。这里总结几个写链表代码的方法和技巧
技巧一:理解指针或引用的含义
C 语言中有指针的概念,而 Java、Python 这样的语言没有指针,而经常谈起“引用”。实际上都是一个意思,都是表示存储对象的内存地址。
如:a = 3
表示变量 a 的指针指向了 3 这个 int 对象。指针其实存储了变量的内存地址。
常用链表代码表示:
p->next = q # 表示 p 结点的后继指针 next 存储了 q 的内存地址
p->netx = p->next->next # 表示 p 的 next 指针存储了 p 的下下个结点的内存地址。
技巧二:警惕指针丢失和内存泄露
如需要在 a 和 b 之间插入结点 x: 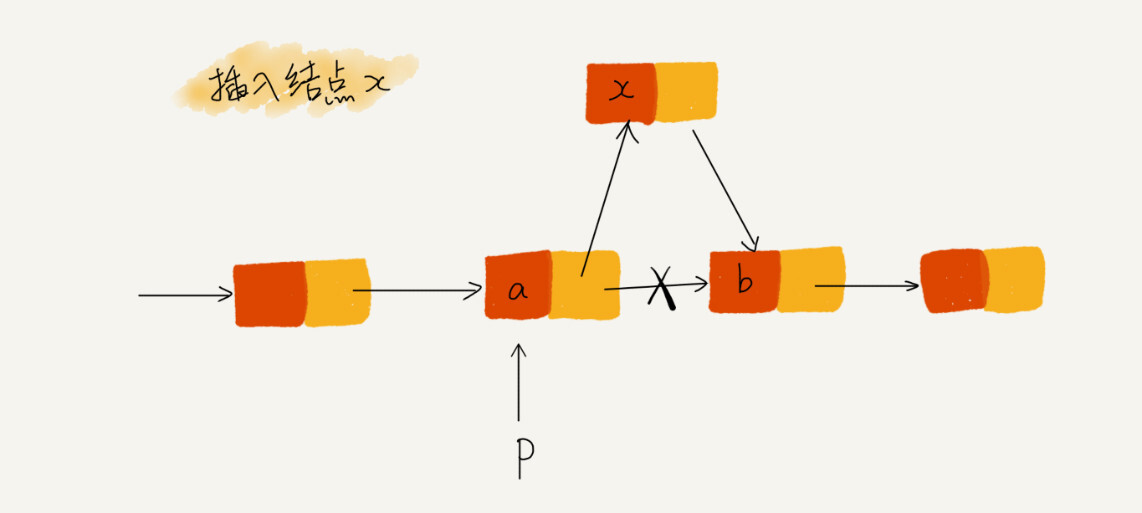
你可能会这样实现:
p->next = x #将 p 的 next 指针指向 x 的结点
x->next = p->next # x 的 next 指针指向 p 的 next 结点
看起来没什么问题,但仔细一看会发现 x 的 next 指针最终指向了自己,整个链表断成了两截。
解决办法是把上面调换一下执行顺序就好了。
技巧三:利用哨兵简化实现难度
上面插入的例子只适用于链表结点大于 1 的情况,如果向一个空链表中插入第一个结点,上面的逻辑就不适用了。需要进行判空操作:
if head == None:
head = new_node
再看删除操作,如果要删除 p 结点的后继结点,只需要这样写:
p->next = p->next->next
但如果要删除最后一个结点,则需要特殊处理:
if head->next == None:
head = None
上面的代码都需要对边界的情况特殊处理,实现非常繁琐,且容易出错,这时候我们可以引入哨兵结点,解决的是链表的边界问题。
哨兵结点并不存储数据,而作为结点头一直存在,不管链表是否为空,head 指针始终指向哨兵结点。我们把这种链表也称为带头链表。 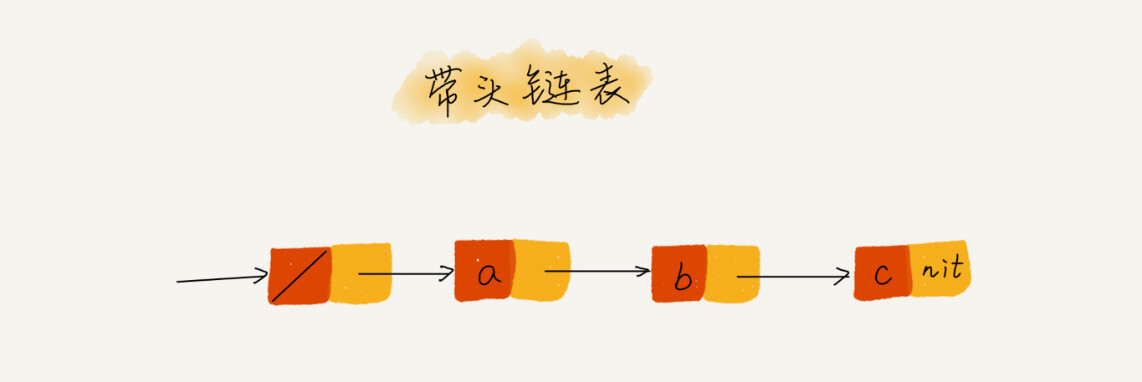
实际上,这种利用哨兵简化编程难度的技巧,在很多代码实现中都有用到,比如插入排序、归并排序、动态规划等。
技巧四:留意边界条件处理
检查链表代码主要考虑以下几个边界问题:
- 链表为空时,代码能否正常工作
- 如果链表中只包含一个结点时,代码能否正常工作
- 如果链表中包含两个结点时,代码能否正常工作
- 代码逻辑在处理头结点和尾结点时,能否正常工作
技巧五:举例画图,辅助思考
画图可以释放一些脑容量,留给更多的逻辑思考,如往一个单链表中插入一个数据: 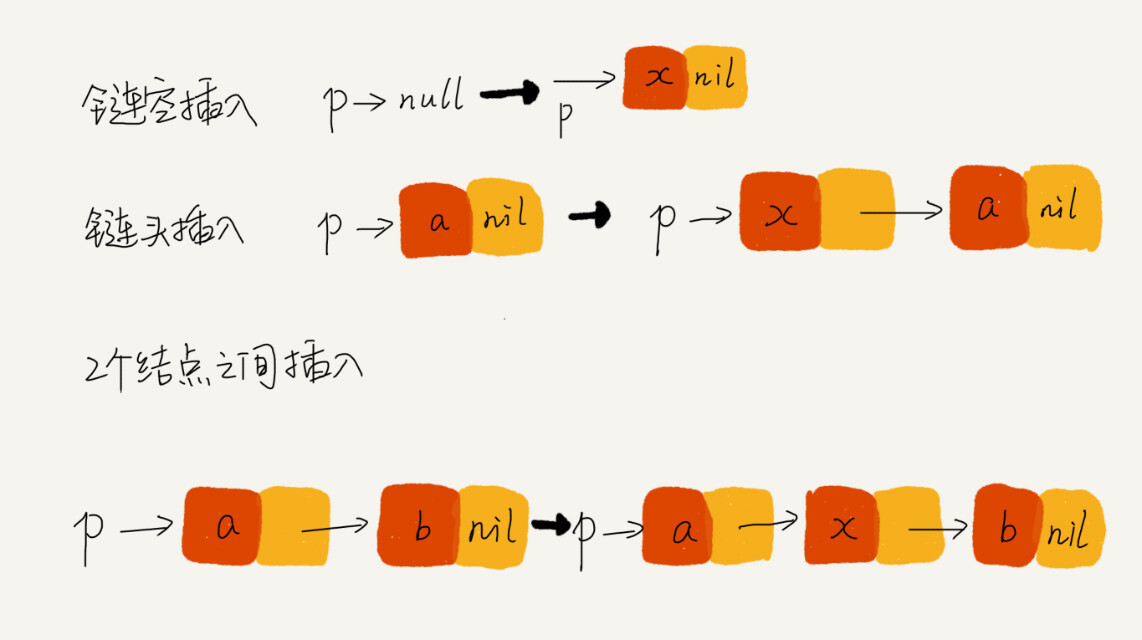
代码实践
from typing import Optional
class Node:
def __init__(self, data: int, next=None):
self.data = data
self._next = next
# Reverse singly-linked list
# 单链表反转
# Note that the input is assumed to be a Node, not a linked list.
def reverse(head: Node) -> Optional[Node]:
reversed_head = None
current = head
while current:
reversed_head, reversed_head._next, current = current, reversed_head, current._next
return reversed_head
# Detect cycle in a list
# 检测环
def has_cycle(head: Node) -> bool:
slow, fast = head, head
while fast and fast._next:
slow = slow._next
fast = fast._next._next
if slow == fast:
return True
return False
# Merge two sorted linked list
# 有序链表合并
def merge_sorted_list(l1: Node, l2: Node) -> Optional[Node]:
if l1 and l2:
p1, p2 = l1, l2
fake_head = Node(None)
current = fake_head
while p1 and p2:
if p1.data <= p2.data:
current._next = p1
p1 = p1._next
else:
current._next = p2
p2 = p2._next
current = current._next
current._next = p1 if p1 else p2
return fake_head._next
return l1 or l2
# Remove nth node from the end
# 删除倒数第n个节点。假设n大于0
def remove_nth_from_end(head: Node, n: int) -> Optional[Node]:
fast = head
count = 0
while fast and count < n:
fast = fast._next
count += 1
if not fast and count < n: # not that many nodes
return head
if not fast and count == n:
return head._next
slow = head
while fast._next:
fast, slow = fast._next, slow._next
slow._next = slow._next._next
return head
# 找到链表中间结点
def find_middle_node(head: Node) -> Optional[Node]:
slow, fast = head, head
fast = fast._next if fast else None
while fast and fast._next:
slow, fast = slow._next, fast._next._next
return slow
# 打印链表
def print_all(head: Node):
nums = []
current = head
while current:
nums.append(current.data)
current = current._next
print("->".join(str(num) for num in nums))
本文首发于 turbobin’s Blog 。转载请注明出处,附上本原文链接, 谢谢合作。

关注微信公众账号「曹当家的」,订阅最新文章推送