Python 标准库
常用Python 标准库
一、os 模块
系统相关
| 方法和变量 | 用途 |
|---|---|
| os.name | 查看当前操作系统的名称。windows平台下返回‘nt’,Linux则返回‘posix’。 |
| os.environ | 获取系统环境变量 |
| os.sep | 当前平台的路径分隔符。在windows下,为‘\’,在POSIX系统中,为‘/’。 |
| os.altsep | 可替代的路径分隔符,在Windows中为‘/’。 |
| os.extsep | 文件名和文件扩展名之间分隔的符号,在Windows下为‘.’。 |
| os.pathsep | PATH环境变量中的分隔符,在POSIX系统中为‘:’,在Windows中为‘;’。 |
| os.linesep | 行结束符。在不同的系统中行尾的结束符是不同的,例如在Windows下为‘\r\n’。 |
| os.devnull | 在不同的系统上null设备的路径,在Windows下为‘nul’,在POSIX下为‘/dev/null’。 |
| os.defpath | 当使用exec函数族的时候,如果没有指定PATH环境变量,则默认会查找os.defpath中的值作为子进程PATH的值。 |
操作文件和目录
| 方法和变量 | 用途 |
|---|---|
| os.getcwd() | 获取当前工作目录,即当前python脚本工作的目录路径 |
| os.chdir(“dirname”) | 改变当前脚本工作目录;相当于shell下cd |
| os.curdir | 返回当前目录: (‘.’) |
| os.pardir | 获取当前目录的父目录字符串名:(‘..’) |
| os.makedirs(‘dir1/dir2’) | 可生成多层递归目录 |
| os.removedirs(‘dirname1’) | 递归删除空目录(要小心) |
| os.mkdir(‘dirname’) | 生成单级目录 |
| os.rmdir(‘dirname’) | 删除单级空目录,若目录不为空则无法删除并报错 |
| os.listdir(‘dirname’) | 列出指定目录下的所有文件和子目录,包括隐藏文件 |
| os.remove(‘filename’) | 删除一个文件 |
| os.rename(“oldname”,”new”) | 重命名文件/目录 |
| os.stat(‘path/filename’) | 获取文件/目录信息 |
| os.path.abspath(path) | 返回path规范化的绝对路径 |
| os.path.split(path) | 将path分割成目录和文件名二元组返回 |
| os.path.splitext() | 分离扩展名。例如os.path.splitext(r”/home/qiye/qiye.txt”),返回结果是一个元组:(‘/home/qiye/qiye’, ‘.txt’)。 |
| os.path.dirname(path) | 返回path的目录。其实就是os.path.split(path)的第一个元素 |
| os.path.basename(path) | 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。 |
| os.path.exists(path或者file) | 如果path存在,返回True;如果path不存在,返回False |
| os.path.isabs(path) | 如果path是绝对路径,返回True |
| os.path.isfile(path) | 如果path是一个存在的文件,返回True。否则返回False |
| os.path.isdir(path) | 如果path是一个存在的目录,则返回True。否则返回False |
| os.path.join(path1[, path2[, …]]) | 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 |
| os.path.getatime(path) | 返回path所指向的文件或者目录的最后存取时间 |
| os.path.getmtime(path) | 返回path所指向的文件或者目录的最后修改时间 |
| os.path.getsize(filename) | 返回文件包含的字符数量 |
os.walk(top, topdown=True, onerror=None, followlinks=False)
walk方法是os模块中非常重要和强大的一个方法。可以帮助我们非常便捷地以递归方式自顶向下或者自底向上的方式遍历目录树,对每一个目录都返回一个三元元组(dirpath, dirnames, filenames)。
- dirpath - 遍历所在目录树的位置,是一个字符串对象
- dirnames - 目录树中的子目录组成的列表,不包括(“.”和”..”)
- filenames - 目录树中的文件组成的列表
下面是一个清除过期 log 文件的例子,log 目录下的日志文件以yyyy-mm-dd格式命名:
import os
import re
from datetime import datetime, date, timedelta
import shutil
logdir_path = r'C:\log'
reg_s = r'20\d{2}-\d{1,2}-\d{1,2}'
today = date.today()
for logdir in os.listdir(logdir_path):
if re.match(reg_s, logdir):
# 字符串转换成日期对象
logdate = datetime.strptime(logdir, '%Y-%m-%d').date()
if logdate < today - timedelta(days=7):
# 删除7天前日志目录
shutil.rmtree(os.path.join(logdir_path, logdir))
print('日志目录 {} 已删除.'.format(logdir))
在文件列表中匹配文件,遍历目录下所有文件,如果不在列表中,则清除文件:
import os
filename = 'imgfile.txt'
with open(filename, 'r') as f:
filelist = map(lambda s: s.strip(), f.readlines())
basedir = r'C:\image'
for rootdir, dirnames, filenames in os.walk(basedir):
# 如果文件不在列表中,则删除
if filenames:
for filename in filenames:
fullname = os.path.join(rootdir, filename)
if not (fullname in filelist):
os.remove(fullname)
print('已删除', fullname)
# 清除一下空目录
if not os.listdir(rootdir):
os.removedirs(rootdir)
执行命令
早期的 Python 版本中,通常使用os模块的system或者popen等方法执行操作系统的命令。最近官方逐渐弃用了这些命令,改用内置的 subprocess 模块执行操作系统相关的命令。不够旧的模块还是可以使用。
os.system(command)
import os
cmd = r'cmd.exe /c start upload.bat'
os.system(cmd) # 调用命令行执行 upload.bat 程序
os.popen(command, [mode, [bufsize]])
开启一个子进程执行command参数指定的命令,在父进程和子进程之间建立一个管道pipe,用于在父子进程间通信。os.popen() 跟 os.system()一样也可以运行操作系统命令,并通过read()方法将命令的结果返回,简而言之就是,os.popen()可以把返回结果存储起来。
>>> os.popen('ipconfig')
<os._wrap_close object at 0x0000000002BB8EF0>
>>> ret = os.popen('ipconfig')
>>> ret.read()
'\nWindows IP 配置\n\n\n以太网适配器 Bluetooth 网络连接 2:\n\n 媒体状态 . . . . . . . . . . . . : 媒体已断开\n 连接特定的 DNS 后缀 . . . . . . . : \n\n无线局域网适配器 无线网络连接
二、sys 模块
sys 模块主要是针对与 Python 解释器相关的的变量和方法,不是操作主机操作系统。
| 属性及方法 | 使用说明 |
|---|---|
| sys.argv | 获取命令行参数列表,第一个元素是程序本身 |
| sys.exit(n) | 退出Python程序,exit(0)表示正常退出。当参数非0时,会引发一个SystemExit异常,可以在程序中捕获该异常 |
| sys.version | 获取Python解释程器的版本信息 |
| sys.maxsize | 最大的Int值,64位平台是2**63 - 1 |
| sys.path | 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 |
| sys.platform | 返回操作系统平台名称 |
| sys.stdin | 输入相关,操作系统标准输入流 |
| sys.stdout | 输出相关,操作系统标准输出流 |
| sys.stderr | 错误相关,操作系统标准错误流 |
| sys.exc_info() | 返回异常信息三元元组 |
| sys.getdefaultencoding() | 获取系统当前编码,默认为utf-8 |
| sys.setdefaultencoding() | 设置系统的默认编码 |
| sys.getfilesystemencoding() | 获取文件系统使用编码方式,默认是utf-8 |
| sys.modules | 以字典的形式返回所有当前Python环境中已经导入的模块 |
| sys.builtin_module_names | 返回一个列表,包含所有已经编译到Python解释器里的模块的名字 |
| sys.copyright | 当前Python的版权信息 |
| sys.flags | 命令行标识状态信息列表。只读。 |
| sys.getrefcount(object) | 返回对象的引用数量 |
| sys.getrecursionlimit() | 返回Python最大递归深度,默认1000 |
| sys.getsizeof(object[, default]) | 返回对象的大小 |
| sys.getswitchinterval() | 返回线程切换时间间隔,默认0.005秒 |
| sys.setswitchinterval(interval) | 设置线程切换的时间间隔,单位秒 |
| sys.getwindowsversion() | 返回当前windwos系统的版本信息 |
| sys.hash_info | 返回Python默认的哈希方法的参数 |
| sys.implementation | 当前正在运行的Python解释器的具体实现,比如CPython |
| sys.thread_info | 当前线程信息 |
sys.getrefcount(object)
这个方法可以返回一个对象被引用的次数。这个次数默认从 1 开始。对象被引用一次,计数就 +1,删除这个对象时,引用计数 -1,当引用计数变成 0 时,Python 会启动垃圾回收机制把这个对象清除,腾出内存。
sys.stdin、sys.stdout、sys.stderr
stdin用于所有的交互式输入(包括input()函数)。stdout用于print()的打印输出或者input()函数的提示符。stderr用于解释器自己的提示信息和错误信息。
print(obj) ==> 等价于 sys.stdout.write(obj+'\n')
input() 和 sys.stdin,以下两组等价:
s = input('Please input something!')
print('Please input something!',) # 逗号表示不换行
s = sys.stdin.readline()[:-1] # -1 可以抛弃输入流中的'\n' 换行符,自己琢磨一下为什么。
实现一个带百分比的进度条:
import sys
import time
def bar(num, total):
rate = num / total
rate_num = int(rate * 100)
r = '\r[%s%s]%d%%' % ("="*num, " "*(100-num), rate_num, )
sys.stdout.write(r)
sys.stdout.flush()
if __name__ == '__main__':
for i in range(0, 101):
time.sleep(0.1)
bar(i, 100)
三、subprocess 模块
使用run()方法调用子进程,执行操作系统命令。
-
subprocess.DEVNULL
一个特殊值,用于传递给stdout、stdin和stderr参数。表示使用
os.devnull作为参数值。 -
subprocess.PIPE
管道,可传递给stdout、stdin和stderr参数。
-
subprocess.STDOUT
特殊值,可传递给stderr参数,表示stdout和stderr合并输出。
>>>s= subprocess.run("ipconfig", stdout=subprocess.PIPE) # 捕获输出
>>>print(s.stdout.decode("GBK"))
四、random 模块
random 模块用于生成伪随机数
- 计算机的伪随机数是由随机种子根据一定的计算方法计算出来的数值。所以,只要计算方法一定,随机种子一定,那么产生的随机数就是固定的。
- 如果用户不设置随机种子,那么随机种子默认来自系统时钟。
基本方法
| 方法 | 说明 |
|---|---|
random.seed(a=None, version=2) | 初始化随机数生成器。如果未提供a或者a=None,则使用系统时间为种子。如果a是一个整数,则作为新的种子。 |
random.choice(seq) | 从非空序列seq中随机选取一个元素。如果seq为空则弹出IndexError异常。 |
random.choices(population, weights=None, \*, cum_weights=None, k=1) | 3.6版本新增。从population集群中随机抽取K个元素。weights是相对权重列表,cum_weights是累计权重,两个参数不能同时存在。 |
random.shuffle(seq) | 洗牌。打乱一个序列内的元素的顺序 |
random.sample(population, k) | 从population样本或集合中随机抽取K个不重复的元素形成新的序列。常用于不重复的随机抽样。返回的是一个新的序列。 |
random.randrange(stop) | 从 range 范围内随机选择一个整数 |
| random.randrange(start, stop[, step]) | 从 range 范围内随机选择一个整数,等同于方法choice(range(start,stop,step)) |
| random.randint(a, b) | 返回一个a <= N <= b的随机整数N。等同于randrange(a, b+1)。 |
| random.random() | 返回一个介于左闭右开[0.0, 1.0)区间的浮点数。 |
| random.uniform(a, b) | 返回一个介于a和b之间的浮点数。如果a>b,则是b到a之间的浮点数。这里的a和b都有可能出现在结果中。 |
| random.gauss(mu, sigma) | 高斯分布 |
| random.normalvariate(mu, sigma) | 正态分布 |
例子
生成一个包含大写字母A-Z和数字0-9的随机4位验证码的程序
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
生成指定长度字母数字随机序列的代码:
import random, string
def gen_random_string(length):
# 数字的个数随机产生
num_of_numeric = random.randint(1,length-1)
# 剩下的都是字母
num_of_letter = length - num_of_numeric
# 随机生成数字
numerics = [random.choice(string.digits) for i in range(num_of_numeric)]
# 随机生成字母
letters = [random.choice(string.ascii_letters) for i in range(num_of_letter)]
# 结合两者
all_chars = numerics + letters
# 洗牌
random.shuffle(all_chars)
# 生成最终字符串
result = ''.join([i for i in all_chars])
return result
if __name__ == '__main__':
print(gen_random_string(64))
五、bisect 模块
bisect模块采用经典的二分算法查找元素。
看下面几个例子:
返回一个数在数组中插入的位置:
import bisect
x = 200
list1 = [1, 3, 6, 24, 55, 78, 454, 555, 1234, 6900]
ret = bisect.bisect(list1, x)
print("返回值: ", ret)
#----------------------
运行结果:
返回值: 6
实现一个由百分制成绩转换为ABCD等级的方法:90 以上是‘A’, 80 -89 是‘B’,
>>> def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
... i = bisect(breakpoints, score)
... return grades[i]
...
>>> [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]]
['F', 'A', 'C', 'C', 'B', 'A', 'A']
六、hashlib 模块
hashlib 模块提供多种安全简便的摘要方法,用于计算一个对象的散列值。比如md5, sha256,sha1 等,可用于对密码加密存储。
hash 对象的方法
hash.update(arg)
用于接受一个 byte 类型的数据,不接受 str 类型。
hash.digest()
返回 bytes 格式的摘要信息
hash.hexdigest()
与digest方法类似,不过返回的是两倍长度的字符串对象,所有的字符都是十六进制的数字。通常用于邮件传输或非二进制环境中。通常我们比较摘要时,比较的就是这个值!
In [1]: import hashlib
In [2]: m = hashlib.sha256()
In [3]: s = "test"
In [4]: m.update(s.encode("utf-8"))
In [5]: m.digest()
Out[5]: b'\x9f\x86\xd0\x81\x88L}e\x9a/\xea\xa0\xc5Z\xd0\x15\xa3\xbfO\x1b+\x0b\x82,\xd1]l\x15\xb0\xf0\n\x08'
In [6]: m.hexdigest()
Out[6]: '9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08'
更简洁的用法:
In [7]: hashlib.sha256(b'test').hexdigest()
Out[7]: '9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08'
hashlib.new(name[, data])
一个通用的方法,name 是算法的字符串名称,data 是可选的 bytes 类型的待 hash 的数据。
In [8]: h = hashlib.new('md5', b'test')
In [9]: h.hexdigest()
Out[9]: '098f6bcd4621d373cade4e832627b4f6'
In [10]: h.name # 哈希对象的算法名称
Out[10]: 'md5'
hashlib 模块的两个常量属性
hashlib.algorithms_guaranteed:所有平台中,模块支持的hash算法列表hashlib.algorithms_available:当前Python解释器环境中,模块支持的hash算法列表
>>> hashlib.algorithms_guaranteed
{'sha256', 'sha3_512', 'sha384', 'sha512', 'sha3_224', 'shake_256', 'shake_128', 'md5', 'sha224', 'blake2b', 'sha3_384', 'blake2s', 'sha3_256', 'sha1'}
>>> hashlib.algorithms_available
{'sha256', 'RIPEMD160', 'sha384', 'MD4', 'DSA-SHA', 'SHA384', 'SHA256', 'shake_128', 'md5', 'dsaWithSHA', 'SHA1', 'blake2b', 'SHA', 'sha3_384', 'md4', 'sha', 'ripemd160', 'whirlpool', 'DSA', 'sha3_512', 'sha512', 'sha3_224', 'shake_256', 'MD5', 'ecdsa-with-SHA1', 'sha224', 'SHA512', 'dsaEncryption', 'SHA224', 'blake2s', 'sha3_256', 'sha1'}
hmac
hmac其实也是 Python 的标准模块,它提供了“加盐”操作,使算法更加标准化,更加安全。
>>> import hmac
>>> message = b'Hello, world!'
>>> key = b'secret'
>>> h = hmac.new(key, message, digestmod='MD5')
>>> # 如果消息很长,可以多次调用h.update(msg)
>>> h.hexdigest()
'fa4ee7d173f2d97ee79022d1a7355bcf'
七、queue 模块
微型轻量级消息队列模块。
- class queue.Queue(maxsize=0) :FIFO 队列构造器。队列满了时,会阻塞队列,知道消费者取走。
- class queue.LifoQueue(maxsize=0):LIFO队列构造器。类似栈结构。
- class queue.PriorityQueue(maxsize=0):优先级队列构造器。通常在这类队列中,元素的优先顺序是按
sorted(list(entries))[0]的结果来定义的,而元素的结构形式通常是(priority_number, data)类型的元组。 - exception queue.Empty:从空的队列里请求元素的时候,弹出该异常。
- exception queue.Full:往满的队列里放入元素的时候,弹出该异常。
>>> import queue
>>> q = queue.Queue(5)
>>> q.put(1)
>>> q.put(2)
>>> q.put(3)
>>> q.get()
1
>>> q.get()
2
>>> q.get()
3
>>> q.get() # 阻塞了
-------------------------------------
>>> q = queue.Queue(5)
>>> q.maxsize
5
>>> q.qsize()
0
>>> q.empty()
True
>>> q.full()
False
>>> q.put(123)
>>> q.put("abc")
>>> q.put(["1","2"])
>>> q.put({"name":"tom"})
>>> q.put(None)
>>> q.put("6") # 阻塞了
-----------------------------------
>>> q = queue.LifoQueue()
>>> q.put(1)
>>> q.put(2)
>>> q.put(3)
>>> q.get()
3
>>> q.get()
2
>>> q.get()
1
-------------------------------------
>>> q = queue.PriorityQueue()
>>> q.put((3,"haha"))
>>> q.put((2,"heihei"))
>>> q.put((1,"hehe"))
>>> q.get()
(1, 'hehe')
>>> q.get()
(2, 'heihei')
>>> q
<queue.PriorityQueue object at 0x0000016825583470>
>>> q.put((4, "xixi"))
>>> q.get()
(3, 'haha')
八、shutil 模块
shutil 是对 os 模块的补充,主要针对文件的拷贝、删除、移动、压缩、和解压操作。
拷贝文件
shutil.copyfileobj(fsrc, fdst[, length=16*1024])
copy文件内容到另一个文件,可以copy指定大小的内容。
>>>import shutil
>>> s =open('fsrc.txt','r')
>>> d=open('fdst.txt','w')
>>> shutil.copyfileobj(s,d,length=16*1024)
shutil.copyfile(src, dst)
copy 整个文件。
shutil.copytree(src,dst,symlinks=False,ignore=None,copy_function=copy2,ignore_dangling_symlinks=False)
递归地复制目录及其子目录的文件和状态信息
- symlinks:指定是否复制软链接。小心陷入死循环。
- ignore:指定不参与复制的文件,其值应该是一个ignore_patterns()方法。
- copy_function:指定复制的模式
# 典型用法
from shutil import copytree, ignore_patterns
copytree(source, destination, ignore=ignore_patterns('*.pyc', 'tmp*'))
copytree('folder1', 'folder2', ignore=ignore_patterns('*.pyc', 'tmp*'))
copytree('f1', 'f2', symlinks=True, ignore=ignore_patterns('*.pyc', 'tmp*'))
删除文件
递归地删除目录及子目录内的文件。
import os, stat
import shutil
def remove_readonly(func, path, _):
"去除文件的只读属性,尝试再次删除"
os.chmod(path, stat.S_IWRITE)
func(path)
shutil.rmtree('directory', onerror=remove_readonly)
移动文件
shutil.move(src, dst)
递归地移动文件,类似mv命令,如果不指定目标路径,就是重命名。
压缩文件
shutil.make_archive(base_name, format[, root_dir[, base_dir[, verbose[, dry_run[, owner[, group[, logger]]]]]]])
创建归档或压缩文件。
base_name:压缩后的文件名。如果不指定绝对路径,则压缩文件保存在当前目录下。这个参数必须指定。format:压缩格式,可以是“zip”, “tar”, “bztar” ,“gztar”,“xztar”中的一种。这个参数也必须指定。root_dir:设置压缩包里的根目录,一般使用默认值,不特别指定。base_dir:要进行压缩的源文件或目录。owner:用户,默认当前用户。group:组,默认当前组。logger:用于记录日志,通常是logging.Logger对象。
example:
import shutil
shutil.make_archive("d:\\3", "zip", base_dir="d:\\1.txt")
解压缩
shutil.unpack_archive(filename[, extract_dir[, format]])
解压缩或解包源文件。
- filename是压缩文档的完整路径
- extract_dir是解压缩路径,默认为当前目录。
- format是压缩格式。默认使用文件后缀名代码的压缩格式。
example:
import shutil
shutil.unpack_archive("d:\\3.zip", "f:\\3", 'zip')
九、json 模块
用于对 python 数据类型和 json 类型进行序列化,主要有以下几个方法:
| 方法 | 功能 |
|---|---|
| json.dump(obj, fp) | 将python数据类型转换并保存到json格式的文件内。 |
| json.dumps(obj) | 将python数据类型转换为json格式的字符串。 |
| json.load(fp) | 从json格式的文件中读取数据并转换为python的类型。 |
| json.loads(s) | 将json格式的字符串转换为python的类型。 |
仔细观察四个方法的名称,很好记忆的,要转化成json就 ‘dump’,要从json转化成Python就 ‘load’;要根据字符串转化就加‘s’,要从文件进行转化就不加 ‘s’。
import json
numbers = [1,3,5,2,7,11]
filename = 'number.json'
with open(filename,'w') as f_obj:
json.dump(numbers,f_obj)
with open(filename) as f_obj:
numbers = json.load(f_obj)
print (numbers)
序列化一个对象:
from email.policy import default
import json
#序列化一个对象:default
class Student():
def __init__(self,name,age,score):
self.name = name
self.age = age
self.score = score
s = Student('张三',22,87)
# print(json.dumps(s)) TypeError: Object of type 'Student' is not JSON serializable
print(json.dumps(s, default=lambda obj:obj.__dict__, ensure_ascii=False,indent=2))
#通常class都有一个__dict__属性,他就是一个dict,用来存储实例变量
# ensure_ascii=False:让中文正常显示
# indent=2:让 json 格式化输出
# 反序列化:object_hook
json_str = '{"name": "Bob", "age": 22, "score": 87}'
print(json.loads(json_str, object_hook=lambda obj:obj))
需要注意的是json模块不支持bytes类型,要先将bytes转换为str格式。
>>> import json
>>> s = "haha"
>>> j = json.dumps(s)
>>> j
'"haha"'
>>> b = b'xixi'
>>> k = json.dumps(b)
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
k = json.dumps(b)
File "C:\Python36\lib\json\__init__.py", line 231, in dumps
return _default_encoder.encode(obj)
File "C:\Python36\lib\json\encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "C:\Python36\lib\json\encoder.py", line 257, in iterencode
return _iterencode(o, 0)
File "C:\Python36\lib\json\encoder.py", line 180, in default
o.__class__.__name__)
TypeError: Object of type 'bytes' is not JSON serializable
网页 json 格式化推荐 Chrome 插件:极简json
十、pickle 模块
pickle 模块是 Python 模块专用的持久化模块,可以持久化包括自定义类在内的各种数据,持久化后的数据是不可认读的。而 json 只能持久化python 内置的几种基本类型,可以以 json 数据格式展示。
主要方法
与 json 模块一模一样的方法名。但是在pickle中dumps()和loads()操作的是bytes类型,而不是json中的str类型;在使用dump()和load()读写文件时,要使用rb或wb模式,也就是只接收bytes类型的数据。
| 方法 | 功能 |
|---|---|
| pickle.dump(obj, file) | 将Python数据转换并保存到pickle格式的文件内 |
| pickle.dumps(obj) | 将Python数据转换为pickle格式的bytes字串 |
| pickle.load(file) | 从pickle格式的文件中读取数据并转换为python的类型 |
| pickle.loads(bytes_object) | 将pickle格式的bytes字串转换为python的类型 |
示例
>>> import pickle
>>> dic = {"k1":"v1","k2":123}
>>> s = pickle.dumps(dic)
>>> type(s)
<class 'bytes'>
>>> s
b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01X\x02\x00\x00\x00v1q\x02X\x02\x00\x00\x00k2q\x03K{u.'
>>> dic2 = pickle.loads(s)
>>> dic2
{'k1': 'v1', 'k2': 123}
>>> type(dic2)
<class 'dict'>
import pickle
data = {
'a': [1, 2.0, 3, 4+6],
'b': ("character string", b"byte string"),
'c': {None, True, False}
}
with open('data.pickle', 'wb') as f:
pickle.dump(data, f)
Pickle可以持久化Python的自定义数据类型,但是在反持久化的时候,必须能够读取到类的定义。
import pickle
class Person:
def __init__(self, n, a):
self.name = n
self.age = a
def show(self):
print(self.name+"_"+str(self.age))
aa = Person("张三", 20)
aa.show()
f = open('d:\\1.txt', 'wb')
pickle.dump(aa, f)
f.close()
# del Person # 注意这行被注释了,如果这里删除了Person,后面 load() 方法会报错。
f = open('d:\\1.txt', 'rb')
bb = pickle.load(f)
f.close()
bb.show()
十一、shelve 模块
shelve 模块是更简单的将 python 对象持久化的方法。shelve 使用起来和字典类似。key 是普通字符串,value 可以是任何形式。
主要方法
shelve 对主要的两个方法:
- shelve.open(filename, flag=’c’, protocol=None, writeback=False):创建或打开一个 shelve 对象(不存在就创建,存在就打开)。
- shelve.close():同步或关闭一个 shelve 对象。
shelve默认打开方式就支持同时读写操作。
import shelve
d = shelve.open('filename') # 打开一个shelve文件
d['key'] = 'data' # 存入数据
data = d['key'] # 获取数据
del d['key'] # 删除某个键值对
flag = 'key' in d # 判断某个键是否在字典内
klist = list(d.keys()) # 列出所有的键
d.close() # 关闭shelve文件
为确保 shelve 对象打开之后都安全关闭,可以使用 with 语句:
with shelve.open('spam') as db:
db['eggs'] = 'eggs'
writeback参数
默认情况下,writeback=False,这时:
>>> import shelve
>>> d = shelve.open("d:\\1")
>>> d['list'] = [0, 1, 2] # 正常工作
>>> d['list']
[0, 1, 2]
>>> d['list'].append(3) # 给它添加个3
>>> d['list'] # 无效!d['list']还是[0, 1, 2]!
[0, 1, 2]
怎么办呢?使用中间变量!
temp = d['list']
temp.append(3) # 修改数据
d['list'] = temp # 再存回去
如果改成writeback=True,可以执行正常的d['list'].append(3)操作,但是这会消耗大量的内存,同时让d.close()操作变得缓慢,因为 shelve 会把所有数据放到缓存中,在执行d.close()的时候,将缓存的所有对象一次性写入磁盘中。
十二、time 模块
在 Python 中,用 3 中方式来表示时间,分别是时间戳、格式化时间字符串、结构化时间。
由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。time模块目前只支持到 2038 年前。如果需要处理范围之外的日期,请使用 datetime 模块。
时间戳
时间戳是从 1970 年 1 月 1日 0 时开始到现在经过的秒数,可以使用time.time()获得,时间戳可以做算术运算。
>>> import time
>>> time.time()
1552135188.834156
结构化时间(struct_time)
使用time.struct_time()方法可以获得一个结构化的时间元组
>>> time.localtime()
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=9, tm_hour=20, tm_min=13, tm_sec=18, tm_wday=5, tm_yday=68, tm_isdst=0)
结构化时间元组共有9个元素,按顺序排列如下表:
| 索引 | 属性 | 取值范围 |
|---|---|---|
| 0 | tm_year(年) | 比如2017 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 61 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
有趣的是,这个struct_time可以通过索引取值,也可以进行分片,还可以通过对于属性名取值
>>> lt = time.localtime()
>>> lt
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=9, tm_hour=20, tm_min=31, tm_sec=27, tm_wday=5, tm_yday=68, tm_isdst=0)
>>> lt[3]
20
>>> lt[1:3]
(3, 9)
>>> lt.tm_mon
3
注意:Python的time类型是不可变类型,所有的时间值都只读,不能改!!
格式化时间字符串
利用time.strftime('%Y-%m-%d %H:%M:%S')等方法可以获得一个格式化时间字符串。
>>> time.strftime('%Y-%m-%d %H:%M:%S')
'2019-03-09 20:36:49'
字符串格式及含义:
| 格式 | 含义 |
|---|---|
| %a | 本地星期名称的简写(如星期四为Thu) |
| %A | 本地星期名称的全称(如星期四为Thursday) |
| %b | 本地月份名称的简写(如八月份为agu) |
| %B | 本地月份名称的全称(如八月份为august) |
| %c | 本地相应的日期和时间的字符串表示(如:15/08/27 10:20:06) |
| %d | 一个月中的第几天(01 - 31) |
| %f | 微秒(范围0.999999) |
| %H | 一天中的第几个小时(24小时制,00 - 23) |
| %I | 第几个小时(12小时制,0 - 11) |
| %j | 一年中的第几天(001 - 366) |
| %m | 月份(01 - 12) |
| %M | 分钟数(00 - 59) |
| %p | 本地am或者pm的标识符 |
| %S | 秒(00 - 61) |
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之 前的所有天数都放在第0周。 |
| %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 |
| %x | 本地相应日期字符串(如15/08/01) |
| %X | 本地相应时间字符串(如08:08:10) |
| %y | 去掉世纪的年份(00 - 99)两个数字表示的年份 |
| %Y | 完整的年份(4个数字表示年份) |
| %z | 与UTC时间的间隔(如果是本地时间,返回空字符串) |
| %Z | 时区的名字(如果是本地时间,返回空字符串) |
| %% | ‘%’字符 |
time 模块常用方法
time.sleep(t)
time 模块最常用的方法,用来睡眠或者暂停线程 t 秒,t 可以是浮点数或者整数。
time.time()
返回当前系统时间戳。时间戳可以做算术运算。
该方法常用于计算程序执行时间。
import time
def func():
time.sleep(1.14)
pass
t1 = time.time()
func()
t2 = time.time()
print(t2 - t1)
time.gmtime()
将一个时间戳转换为 UTC 时区的结构化时间。
>>> t = time.time() - 10000
>>> time.gmtime(t)
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=9, tm_hour=10, tm_min=3, tm_sec=26, tm_wday=5, tm_yday=68, tm_isdst=0)
time.ctime()
把一个时间戳转化为本地时间的格式化字符串。默认使用time.time()作为参数。
>>> time.ctime()
'Sat Mar 9 20:53:21 2019'
time.asctime()
把一个结构化时间转换为Sun Aug 23 14:31:59 2017这种形式的格式化时间字符串。默认将time.localtime()作为参数。
time.mktime(t)
将一个结构化时间转化为时间戳。time.mktime()执行与gmtime(),localtime()相反的操作,它接收struct_time对象作为参数,返回用秒数表示时间的浮点数。如果输入的值不是一个合法的时间,将触发OverflowError或ValueError。
time.strftime(format [, t])
返回格式化字符串表示的当地时间。把一个struct_time(如time.localtime()和time.gmtime()的返回值)转化为格式化的时间字符串,显示的格式由参数format决定。如果未指定t,默认传入time.localtime()。如果元组中任何一个元素越界,就会抛出ValueError的异常。
>>> time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime())
'2019-03-09 12:58:16'
time.strptime(string[,format])
将格式化时间字符串转化成结构化时间。该方法是time.strftime()方法的逆操作。time.strptime()方法根据指定的格式把一个时间字符串解析为时间元组。要注意的是,你提供的字符串要和format参数的格式一一对应,如果string中日期间使用“-”分隔,format中也必须使用“-”分隔,时间中使用冒号“:”分隔,后面也必须使用冒号分隔,否则会报格式不匹配的错误。并且值也要在合法的区间范围内,千万不要整出14个月来。
>>> import time
>>> stime = "2017-09-26 12:11:30"
>>> st = time.strptime(stime,"%Y-%m-%d %H:%M:%S")
>>> st
time.struct_time(tm_year=2017, tm_mon=9, tm_mday=26, tm_hour=12, tm_min=11, tm_sec=30, tm_wday=1, tm_yday=269, tm_isdst=-1)
不同时间格式的转化
| 从 | 到 | 方法 |
|---|---|---|
| 时间戳 | UTC结构化时间 | gmtime() |
| 时间戳 | 本地结构化时间 | localtime() |
| UTC结构化时间 | 时间戳 | calendar.timegm() |
| 本地结构化时间 | 时间戳 | mktime() |
| 结构化时间 | 格式化字符串 | strftime() |
| 格式化字符串 | 结构化时间 | strptime() |
十三、datetime 模块
与time模块相比,datetime模块提供的接口更直观、易用,功能也更加强大。
datetime 可表示的年份范围为 1 ~ 9999。
主要类:
| 类名 | 描述 |
|---|---|
| datetime.date | 日期类 |
| datetime.time | 时间类 |
| datetime.datetime | 日期与时间类 |
| datetime.timedelta | 表示两个date、time、datetime实例之间的时间差 |
| datetime.tzinfo | 时区相关信息对象的抽象基类。 |
| datetime.timezone | Python3.2中新增的功能,实现tzinfo抽象基类的类,表示与UTC的固定偏移量 |
常量:
datetime.MINYEAR:
datetime.date或datetime.datetime对象所允许的年份的最小值,该值为1。
datetime.MAXYEAR:
datetime.date或datetime.datetime对象所允许的年份的最大值,该值为9999。
datetime.date类
datetime.date(year, month, day)
datetime模块下的日期类,只能处理年月日这种日期时间,不能处理时分秒。
在构造datetime.date对象的时候需要传递下面的参数:
| 参数名称 | 取值范围 |
|---|---|
| year | [MINYEAR, MAXYEAR] |
| month | [1, 12] |
| day | [1, 指定年份的月份中的天数] |
主要属性和方法:
| 类方法/属性名称 | 描述 |
|---|---|
| date.max | date对象所能表示的最大日期:9999-12-31 |
| date.min | date对象所能表示的最小日期:00001-01-01 |
| date.resolution | date对象表示的日期的最小单位:天 |
| date.today() | 返回一个表示当前本地日期的date对象 |
| date.fromtimestamp(timestamp) | 根据给定的时间戳,返回一个date对象 |
| d.year | 年 |
| d.month | 月 |
| d.day | 日 |
| d.replace(year[, month[, day]]) | 生成并返回一个新的日期对象,原日期对象不变 |
| d.timetuple() | 返回日期对应的time.struct_time对象 |
| d.toordinal() | 返回日期是是自 0001-01-01 开始的第多少天 |
| d.weekday() | 返回日期是星期几,[0, 6],0表示星期一 |
| d.isoweekday() | 返回日期是星期几,[1, 7], 1表示星期一 |
| d.isocalendar() | 返回一个元组,格式为:(year, weekday, isoweekday) |
| d.isoformat() | 返回‘YYYY-MM-DD’格式的日期字符串 |
| d.strftime(format) | 返回指定格式的日期字符串,与time模块的strftime(format, struct_time)功能相同 |
示例:
>>> from datetime import date
>>> date.max
datetime.date(9999, 12, 31)
>>> date.resolution
datetime.timedelta(1)
>>> d = date.today()
>>> d
datetime.date(2019, 3, 9)
>>> d.day
9
>>> d.timetuple()
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=9, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=5, tm_yday=68, tm_isdst=-1)
>>> d.isocalendar()
(2019, 10, 6)
>>> d.isoformat()
'2019-03-09'
>>> d.strftime("%Y-%m-%d")
'2019-03-09'
>>> d.toordinal()
737127
datetime.time类
datetime.time(hour, [minute[, second, [microsecond[, tzinfo]]]])
datetime模块下的时间类,只能处理时分秒。
在构造datetime.time对象的时候需要传递下面的参数:
| 参数名称 | 取值范围 |
|---|---|
| hour | [0, 23] |
| minute | [0, 59] |
| second | [0, 59] |
| microsecond | [0, 1000000] |
| tzinfo | tzinfo的子类对象,如timezone类的实例 |
主要属性和方法:
| 类方法/属性名称 | 描述 |
|---|---|
| time.max | time类所能表示的最大时间:time(23, 59, 59, 999999) |
| time.min | time类所能表示的最小时间:time(0, 0, 0, 0) |
| time.resolution | 时间的最小单位,即两个不同时间的最小差值:1微秒 |
| t.hour | 时 |
| t.minute | 分 |
| t.second | 秒 |
| t.microsecond | 微秒 |
| t.tzinfo | 返回传递给time构造方法的tzinfo对象,如果该参数未给出,则返回None |
| t.replace(hour[, minute[, second[, microsecond[, tzinfo]]]]) | 生成并返回一个新的时间对象,原时间对象不变 |
| t.isoformat() | 返回一个‘HH:MM:SS.%f’格式的时间字符串 |
| t.strftime() | 返回指定格式的时间字符串,与time模块的strftime(format, struct_time)功能相同 |
使用范例:
>>> from datetime import time
>>> t = time(12, 15, 40, 6666)
>>> t
datetime.time(12, 15, 40, 6666)
>>> t.isoformat()
'12:15:40.006666'
>>> t.replace(21)
datetime.time(21, 15, 40, 6666)
>>> t.isoformat()
'12:15:40.006666'
>>> t.strftime('%H:%M:%S')
'12:15:40'
datetime.datetime类
datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None)
datetime模块下的日期时间类,你可以理解为datetime.time和datetime.date的组合类。
在构造datetime.datetime对象的时候需要传递下面的参数:
| 参数名称 | 取值范围 |
|---|---|
| year | [MINYEAR, MAXYEAR] |
| month | [1, 12] |
| day | [1, 指定年份的月份中的天数] |
| hour | [0, 23] |
| minute | [0, 59] |
| second | [0, 59] |
| microsecond | [0, 1000000] |
| tzinfo | tzinfo的子类对象,如timezone类的实例 |
主要属性和方法:
| 类方法/属性名称 | 描述 |
|---|---|
| datetime.today() | 返回一个表示当前本期日期时间的datetime对象 |
| datetime.now([tz]) | 返回指定时区日期时间的datetime对象,如果不指定tz参数则结果同上 |
| datetime.utcnow() | 返回当前utc日期时间的datetime对象 |
| datetime.fromtimestamp(timestamp[, tz]) | 根据指定的时间戳创建一个datetime对象 |
| datetime.utcfromtimestamp(timestamp) | 根据指定的时间戳创建一个datetime对象 |
| datetime.combine(date, time) | 把指定的date和time对象整合成一个datetime对象 |
| datetime.strptime(date_str, format) | 将时间字符串转换为datetime对象 |
| dt.year, dt.month, dt.day | 年、月、日 |
| dt.hour, dt.minute, dt.second | 时、分、秒 |
| dt.microsecond, dt.tzinfo | 微秒、时区信息 |
| dt.date() | 获取datetime对象对应的date对象 |
| dt.time() | 获取datetime对象对应的time对象, tzinfo 为None |
| dt.timetz() | 获取datetime对象对应的time对象,tzinfo与datetime对象的tzinfo相同 |
| dt.replace() | 生成并返回一个新的datetime对象,如果所有参数都没有指定,则返回一个与原datetime对象相同的对象 |
| dt.timetuple() | 返回datetime对象对应的tuple(不包括tzinfo) |
| dt.utctimetuple() | 返回datetime对象对应的utc时间的tuple(不包括tzinfo) |
| dt.timestamp() | 返回datetime对象对应的时间戳,Python 3.3才新增的 |
| dt.toordinal() | 同date对象 |
| dt.weekday() | 同date对象 |
| dt.isocalendar() | 同date对象 |
| dt.isoformat([sep]) | 返回一个‘%Y-%m-%d’字符串 |
| dt.ctime() | 等价于time模块的time.ctime(time.mktime(d.timetuple())) |
| dt.strftime(format) | 返回指定格式的时间字符串 |
示例:
>>> from datetime import datetime, timezone
>>> now = datetime.now() # 获取当前本机时间
>>> print(now)
2019-03-09 22:01:50.586884
>>> dt = datetime(2019,3,9,22,20) #获取指定日期时间
>>> print(dt)
2019-03-09 22:20:00
>>> dt.timestamp() # datetime转换成 timestamp
1552141200.0
>>> t = 1552141200.0
>>> print(datetime.fromtimestamp(t)) # timestamp转换为datetime
2019-03-09 22:20:00
>>> print(datetime.utcfromtimestamp(t)) # UTC时间
2019-03-09 14:20:00
>>> cday = datetime.strptime('2019-3-9 18:19:59', '%Y-%m-%d %H:%M:%S') #str转换为datetime
>>> print(cday)
2019-03-09 18:19:59
>>> print(now.strftime('%a, %b %d %H:%M')) # datetime转换为str
Sat, Mar 09 22:01
>>> utcnow = datetime.now(timezone.utc) # 本地时间转换为UTC时间
>>> print(utcnow)
2019-03-09 14:14:49.690487+00:00
datetime.timedelta类
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, hours=0, weeks=0)
timedelta对象表示两个不同时间之间的差值。可以对datetime.date, datetime.time和datetime.datetime对象做算术运算。
| 类方法/属性名称 | 描述 |
|---|---|
| timedelta.min | timedelta(-999999999) |
| timedelta.max | timedelta(days=999999999, hours=23, minutes=59, seconds=59, microseconds=999999) |
| timedelta.resolution | timedelta(microseconds=1) |
| td.days | 天 [-999999999, 999999999] |
| td.seconds | 秒 [0, 86399] |
| td.microseconds | 微秒 [0, 999999] |
| td.total_seconds() | 时间差中包含的总秒数,等价于: td / timedelta(seconds=1) |
示例:
>>> from datetime import datetime, timedelta
>>> now = datetime.now()
>>> dt = now + timedelta(days=-3, hours=10) # 3 天前的往后 10 小时
>>> print(dt)
2019-03-07 08:01:50.586884
>>> days = (now - dt).days
>>> days
2
十四、logging 模块
logging 使用场景
Python 官方推荐使用场景
| 任务场景 | 最佳工具 |
|---|---|
| 普通情况下,在控制台显示输出 | print() |
| 报告正常程序操作过程中发生的事件 | logging.info()(或者更详细的logging.debug()) |
| 发出有关特定事件的警告 | warnings.warn()或者logging.warning() |
| 报告错误 | 弹出异常 |
| 在不引发异常的情况下报告错误 | logging.error(), logging.exception()或者logging.critical() |
logging模块定义了下表所示的日志级别,按事件严重程度由低到高排列(注意是全部大写!因为它们是常量。):
| 级别 | 级别数值 | 使用时机 |
|---|---|---|
| DEBUG | 10 | 详细信息,常用于调试。 |
| INFO | 20 | 程序正常运行过程中产生的一些信息。 |
| WARNING | 30 | 警告用户,虽然程序还在正常工作,但有可能发生错误。 |
| ERROR | 40 | 由于更严重的问题,程序已不能执行一些功能了。 |
| CRITICAL | 50 | 严重错误,程序已不能继续运行。 |
默认级别是WARNING,表示只有WARING和比WARNING更严重的事件才会被记录到日志内,低级别的信息会被忽略。因此,默认情况下,DEBUG和INFO会被忽略,WARING、ERROR和CRITICAL会被记录。
在控制台打印
在什么都不配置和设定的情况下,logging会简单地将日志打印在显示器上
>>> import logging
>>> logging.info('hello world') # 这行不会被打印,因为级别低于默认级别
>>> logging.warning('hell world') # 消息会被打印到控制台上
WARNING:root:hell world
默认情况下,打印出来的内容包括日志级别、调用者和具体的日志信息。所有的这些内容都是可以自定义的。
记录到文件中
使用logging.basicConfig()方法。
>>> import logging
>>> logging.basicConfig(filename='example.log',level=logging.DEBUG)
>>> logging.debug('This message should go to the log file')
>>> logging.info('So should this')
>>> logging.warning('And this, too')
然后打开本地的example.log文件,可以看到下面的日志消息:
DEBUG:root:This message should go to the log file
INFO:root:So should this
WARNING:root:And this, too
如果想在命令行调用时设置日志级别,可以使用下面的选项:
--log=INFO
默认情况下,日志会不断追加到文件末尾,如果需要每次清空文件,然后再写入日子,可以设置如下:
>>> logging.basicConfig(filename='example.log', filemode='w', level=logging.DEBUG)
消息格式
要控制消息格式,获得更多的花样,可以提供format参数:
import logging
logging.basicConfig(filename='example.log', format='%(asctime)s-%(levelname)s:%(message)s', level=logging.DEBUG)
logging.debug('This message should appear on the console')
logging.info('So should this')
logging.warning('And this, too')
打开本地example.log文件,输出如下:
2019-03-09 23:53:43,710-DEBUG:This message should appear on the console
2019-03-09 23:53:49,036-INFO:So should this
2019-03-09 23:53:54,453-WARNING:And this, too
- 附加时间信息,加入参数
%(asctime)s; - 显示日志级别,使用参数
%(levelname)s。
自定义时间格式,可以使用 datefmt参数:
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.')
输出:
03/10/2019 12:00:07 AM is when this event was logged.
格式化参数表:
| 属性 | 格式 | 描述 |
|---|---|---|
| asctime | %(asctime)s | 日志产生的时间,默认格式为2003-07-08 16:49:45,896 |
| created | %(created)f | time.time()生成的日志创建时间戳 |
| filename | %(filename)s | 生成日志的程序名 |
| funcName | %(funcName)s | 调用日志的函数名 |
| levelname | %(levelname)s | 日志级别 (‘DEBUG’, ‘INFO’, ‘WARNING’, ‘ERROR’, ‘CRITICAL’) |
| levelno | %(levelno)s | 日志级别对应的数值 |
| lineno | %(lineno)d | 日志所针对的代码行号(如果可用的话) |
| module | %(module)s | 生成日志的模块名 |
| msecs | %(msecs)d | 日志生成时间的毫秒部分 |
| message | %(message)s | 具体的日志信息 |
| name | %(name)s | 日志调用者 |
| pathname | %(pathname)s | 生成日志的文件的完整路径 |
| process | %(process)d | 生成日志的进程ID(如果可用) |
| processName | %(processName)s | 进程名(如果可用) |
| thread | %(thread)d | 生成日志的线程ID(如果可用) |
| threadName | %(threadName)s | 线程名(如果可用) |
高级用法
logging模块采用了模块化设计,主要包含四种组件:
Loggers:记录器,提供应用程序代码能直接使用的接口;
Handlers:处理器,将记录器产生的日志发送至目的地;
Filters:过滤器,提供更好的粒度控制,决定哪些日志会被输出;
Formatters:格式化器,设置日志内容的组成结构和消息字段。
日志流程图:
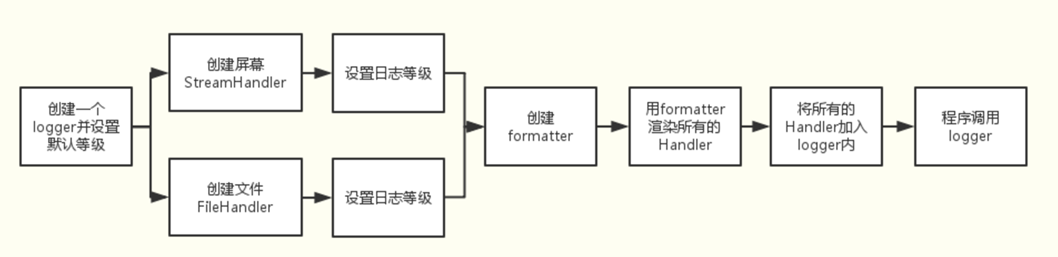
1. Loggers 记录器
使用 Loggers 处理器,必须先获取一个 Loggers 实例(建议以模块名称命名logger实例)
import logging
logger = logging.getLogger(__name__)
注意,
getLogger()方法返回一个logger对象的引用,并以你提供的name参数命名,如果未提供名字,那么默认为‘root’。使用同样的name参数,多次调用getLogger(),将返回同样的logger对象(幂等性)。
下面是最常用的配置方法:
Logger.setLevel():设置日志记录级别Logger.addHandler()和Logger.removeHandler():为logger对象添加或删除handler处理器对象。Logger.addFilter()和Logger.removeFilter():为为logger对象添加或删除filter过滤器对象。
创建消息:
Logger.debug(),Logger.info(),Logger.warning(),Logger.error(),and Logger.critical():创建对应级别的日志,但不一定会被记录。Logger.exception():创建一个类似Logger.error()的日志消息。不同的是Logger.exception()保存有一个追踪栈。该方法只能在异常handler中调用。Logger.log():显式的创建一条日志,是前面几种方法的通用方法。
2. Handlers 处理器
logging模块使用较多的handlers有两个,StreamHandler和FileHandler。
StreamHandler
标准输出stdout(如显示器)分发器。
创建方法: sh = logging.StreamHandler(stream=None)
FileHandler
将日志保存到磁盘文件的处理器。
创建方法: fh = logging.FileHandler(filename, mode='a', encoding=None, delay=False)
handlers对象有下面的方法:
setLevel():和logger对象的一样,设置日志记录级别。那为什么要设置两层日志级别呢?logger对象的日志级别是全局性的,对所有handler都有效,相当于默认等级。而handlers的日志级别只对自己接收到的logger传来的日志有效,进行了更深一层的过滤。setFormatter():设置当前handler对象使用的消息格式。addFilter()和removeFilter():配置或删除一个filter过滤对象
3. Filter 过滤器
创建方法: filter = logging.Filter(name='')
例如:
filter = logging.Filter('mylogger.child1.child2')
fh.addFilter(filter)
则只会输出下面格式的日志,注意其用户名:
2017-09-27 16:27:46,227 - mylogger.child1.child2 - DEBUG - logger1 debug message
2017-09-27 16:27:46,227 - mylogger.child1.child2 - DEBUG - logger1 debug message
2017-09-27 16:27:46,227 - mylogger.child1.child2 - DEBUG - logger1 debug message
2017-09-27 16:27:46,227 - mylogger.child1.child2 - DEBUG - logger1 debug message
5. Formatters 格式化器
Formatter对象用来最终设置日志信息的顺序、结构和内容。其构造方法为:
ft = logging.Formatter.__init__(fmt=None, datefmt=None, style=’%’)
如果不指定datefmt,那么它默认是%Y-%m-%d %H:%M:%S样式的。
配置日志模块
有三种配置logging的方法:
- 创建loggers、handlers和formatters,然后使用Python的代码调用上面介绍过的配置函数。
- 创建一个logging配置文件,然后使用
fileConfig()方法读取它。 - 创建一个配置信息字典然后将它传递给
dictConfig()方法。
第一种方法:
#simple_logging_module.py
import logging
# 创建logger记录器
logger = logging.getLogger('simple_example')
logger.setLevel(logging.DEBUG)
# 创建一个控制台处理器,并将日志级别设置为debug。
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 创建formatter格式化器
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 将formatter添加到ch处理器
ch.setFormatter(formatter)
# 将ch添加到logger
logger.addHandler(ch)
# 然后就可以开始使用了!
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
在命令行中运行上面的代码,输出结果如下:
$ python simple_logging_module.py
2005-03-19 15:10:26,618 - simple_example - DEBUG - debug message
2005-03-19 15:10:26,620 - simple_example - INFO - info message
2005-03-19 15:10:26,695 - simple_example - WARNING - warn message
2005-03-19 15:10:26,697 - simple_example - ERROR - error message
2005-03-19 15:10:26,773 - simple_example - CRITICAL - critical message
第二种方法:
# simple_logging_config.py
import logging
import logging.config
logging.config.fileConfig('logging.conf') # 读取config文件
# 创建logger记录器
logger = logging.getLogger('simpleExample')
# 使用日志功能
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
其中的logging.conf配置文件内容如下:
[loggers]
keys=root,simpleExample
[handlers]
keys=consoleHandler
[formatters]
keys=simpleFormatter
[logger_root]
level=DEBUG
handlers=consoleHandler
[logger_simpleExample]
level=DEBUG
handlers=consoleHandler
qualname=simpleExample
propagate=0
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=simpleFormatter
args=(sys.stdout,)
[formatter_simpleFormatter]
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
datefmt=
在命令行中执行代码,结果如下:
$ python simple_logging_config.py
2005-03-19 15:38:55,977 - simpleExample - DEBUG - debug message
2005-03-19 15:38:55,979 - simpleExample - INFO - info message
2005-03-19 15:38:56,054 - simpleExample - WARNING - warn message
2005-03-19 15:38:56,055 - simpleExample - ERROR - error message
2005-03-19 15:38:56,130 - simpleExample - CRITICAL - critical message
第三种方法:
Python官方更推荐第三种新的配置方法,类字典形式的配置信息,因为Python的字典运用形式多样,操作灵活。比如,你可以通过JSON格式保存字典,或者YAML格式保存信息,然后读取成字典。当然,你也可以直接在Python代码里编写传统的带有配置信息的字典。一切都是基于键值对形式的就OK。
下面的例子就是基于YAML配置文件的日志。logging.conf.yaml配置文件内容如下:
version: 1
formatters:
simple:
format: '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
handlers:
console:
class: logging.StreamHandler
level: DEBUG
formatter: simple
stream: ext://sys.stdout
loggers:
simpleExample:
level: DEBUG
handlers: [console]
propagate: no
root:
level: DEBUG
handlers: [console]
这里要先通过pip安装yaml模块:
pip install pyyaml
yaml模块的使用很简单,使用open()方法打开一个yaml文件对象,然后使用yaml的load()方法将文件内容读成一个Python的字典对象。最后我们根据这个字典对象,使用logging.conf的dictConfig()方法,获取配置信息。如下代码所示:
import logging
import logging.config
import yaml
# 通过yaml文件配置logging
f = open("logging.conf.yaml")
dic = yaml.load(f)
f.close()
logging.config.dictConfig(dic)
# 创建logger
logger = logging.getLogger('simpleExample')
# 输出日志
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
输出结果:
2017-09-27 17:41:09,241 - simpleExample - DEBUG - debug message
2017-09-27 17:41:09,242 - simpleExample - INFO - info message
2017-09-27 17:41:09,242 - simpleExample - WARNING - warn message
2017-09-27 17:41:09,242 - simpleExample - ERROR - error message
2017-09-27 17:41:09,242 - simpleExample - CRITICAL - critical message
十五、collections 模块
collections 提供了很多有用的集合类。
namedtuple
nemedtuple是一个函数,它用来创建一个自定义的 tuple 对象,它可以实现用属性而不是索引来引用某个元素。
比如定义一个二维坐标:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
类似的,也可以用来表示一个圆:
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
deque 对 list 做了改进,是一个实现了高效的插入和删除操作的双向列表,适合用于队列和栈。
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
我们常使用的dict中的 key 是无序的,当对dict做迭代时,无法保证 Key 的顺序。
如果要保证 Key 的顺序,可以使用 OrderedDict。
OrderedDict 并不是按照内部 key 排序,而是按照先进先出的顺序排序,当容量超出限制时,会先删除最早添加的 Key。
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> d = OrderedDict()
>>> d['b'] = 2
>>> d['c'] = 3
>>> d['a'] = 1
>>> d
OrderedDict([('b', 2), ('c', 3), ('a', 1)])
ChainMap
ChainMap可以把一组 dict 串起来组成一组逻辑上的 dict,当查找某个元素时,会按照ChainMap的顺序依次在dict中寻找。比如:
from collections import ChainMap
combined = ChainMap(dictC, dictB, dictA)
当查找 combined["key"]时,元素 key 会先在dictC中找,如果不存在,会在dictB中找,如果还未找到,会在dictA中找。
Counter
Counter 是一个简单的计数器。
比如统计每个字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
十六、 re 模块
match 方法
判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None,常见的判断方法是:
import re
test = '用户输入的字符串'
if re.match(r'正则表达式', test):
print('ok')
else:
print('failed')
split 方法
切分字符串。
>>> import re
>>> 'a b c'.split(' ') # 无法切分空格
['a', 'b', '', '', 'c']
>>> re.split(r'\s+', 'a b c') # 识别连续的空格
['a', 'b', 'c']
>>> re.split(r'[\s\,]+', 'a,b, c d') # 识别空格和逗号
['a', 'b', 'c', 'd']
>>> re.split(r'[\s\,\;]+', 'a,b;; c d') # 识别空格,逗号,和分号
['a', 'b', 'c', 'd']
分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')
查找和替换
使用re.findall()方法查找匹配的字符串,返回一个列表
>>> import re
>>> s = 'We will fly to Thailand on 2016/10/31'
>>> pattern = r'\d+'
>>> re.findall(pattern, s)
['2016', '10', '31']
>>> re.search(pattern, s)
<_sre.SRE_Match object at 0x03A8FD40>
>>> re.search(pattern, s).group()
'2016'
替换使用re.sub(),可以替换某些字符串:
>>> s = "I like {color} car."
>>> re.sub(r'\{color\}','blue',s)
'I like blue car.'
>>> s = 'We will fly to Thailand on 10/31/2016'
>>> re.sub('(\d+)/(\d+)/(\d+)', r'\3-\1-\2', s) # 一共匹配了3个分组,然后重新排序
'We will fly to Thailand on 2016-10-31'
另外一个例子:
s = "Tom is talking to Jerry."
name1 = "Tom"
name2 = "Jerry"
pattern = r'(.*)({0})(.*)({1})(.*)'.format(name1, name2)
print re.sub(pattern, r'\1\4\3\2\5', s)
# Jerry is talking to Tom.
自定义替换函数:
def change_date(m):
from calendar import month_abbr
mon_name = month_abbr[int(m.group(1))]
return '{} {} {}'.format(m.group(2), mon_name, m.group(3))
s = 'We will fly to Thailand on 10/31/2016'
pattern = r'(\d+)/(\d+)/(\d+)'
print re.sub(pattern, change_date, s)
# We will fly to Thailand on 31 Oct 2016
升级版例子:
def match_case(word):
def replace(m):
text = m.group()
if text.isupper():
return word.upper()
elif text.islower():
return word.lower()
elif text[0].isupper():
return word.capitalize()
else:
return word
return replace
s = "LOVE PYTHON, love python, Love Python"
print re.sub('python', match_case('money'), s, flags=re.IGNORECASE)
# LOVE MONEY, love money, Love Money
编译
如果一个正则表达式需要重复使用很多次,为了提高效率,需要进行预编译:
>>> import re
# 编译:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 使用:
>>> re_telephone.match('010-12345').groups()
('010', '12345')
>>> re_telephone.match('010-8086').groups()
('010', '8086')
编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
本文首发于 turbobin’s Blog 。转载请注明出处,附上本原文链接, 谢谢合作。

关注微信公众账号「曹当家的」,订阅最新文章推送